知乎数据分析(知乎数据分析培训技巧)
7 天前浏览
本文重点介绍知乎数据分析平台对Druid的查询优化。通过一套自研的缓存机制和查询转换,目前平台长期满足业务指标和灵活分析的需求大数据培训是骗局,降低了数据开发者的开发成本。
背景
知乎作为知名的中文知识内容平台,业务增长速度快,产品迭代快。如何满足业务快速扩张中灵活的分析需求,是知乎数据平台团队面临的一大挑战。
知乎数据平台团队基于开源Druid搭建了一个自助数据分析平台。经过研发迭代,目前支持整个业务的数据分析需求,是业务数据分析的重要工具。
目前平台主要能力如下:
统一数据源管理,支持Hive表摄取离线数仓和Kafka流式实时数仓自助报表配置,支持多维分析报表、留存分析报表多维多索引灵活组合分析,秒级响应速度,支持嵌套“and”和“or”条件过滤,自助仪表盘,配置开发平台接口,统一数据权限管理,为其他系统提供数据服务
目前业务使用平台数据如下:
自助配置仪表盘数量:495个,仪表盘总报表:2399个每日请求3w+ 为A/B、渠道管理、APM、数据邮件等系统提供数据API数据分析平台架构
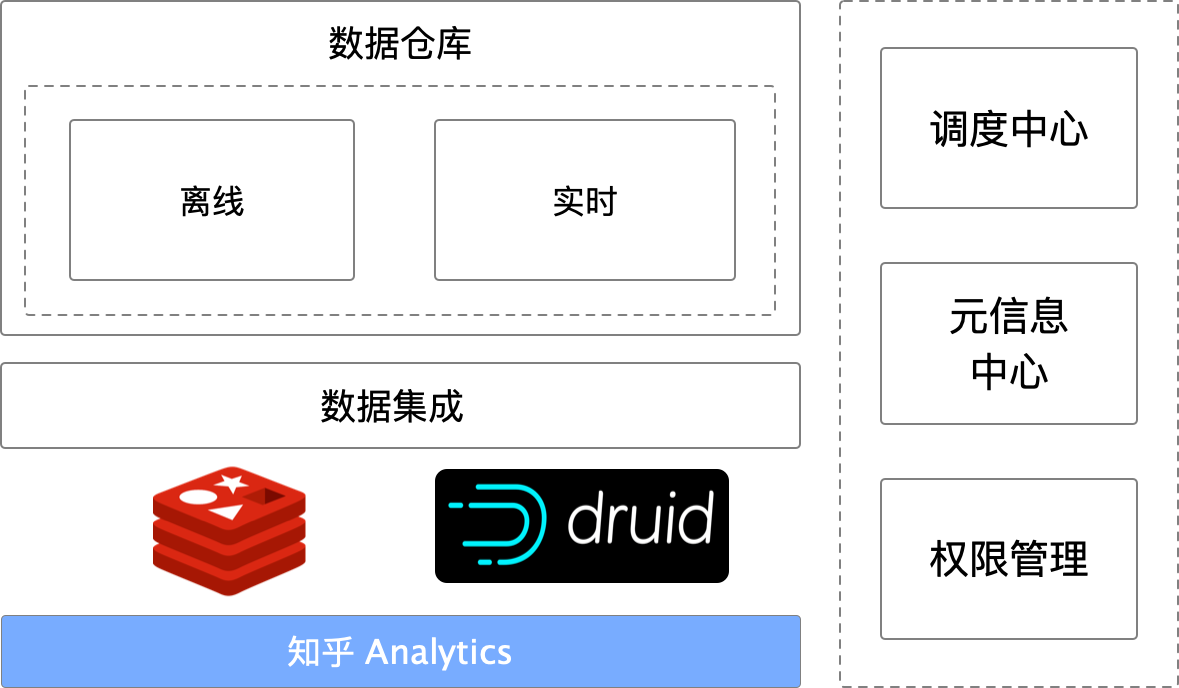
知乎实时多维分析平台架构
技术选择 - 德鲁伊
Druid 是一种数据存储,可提供对历史和实时数据的亚秒级查询。
Druid 支持低延迟数据摄取、灵活的数据探索和分析、高性能数据聚合以及轻松的水平扩展。适用于数据量大、扩展性要求高的分析查询系统。
Druid 整体架构
Druid 数据结构和架构简介
德鲁伊数据结构
查询服务的相关组件
内部组件
外部组件
平台的演变
Druid 查询量很大
在 Druid 成为主查询引擎后,我们发现在大查询量的场景下直接查询 Druid 存在一些弊端。最大的痛点是查询响应慢。
缓存查询结果
为了提高整体查询速度,我们引入了 Redis 作为缓存。
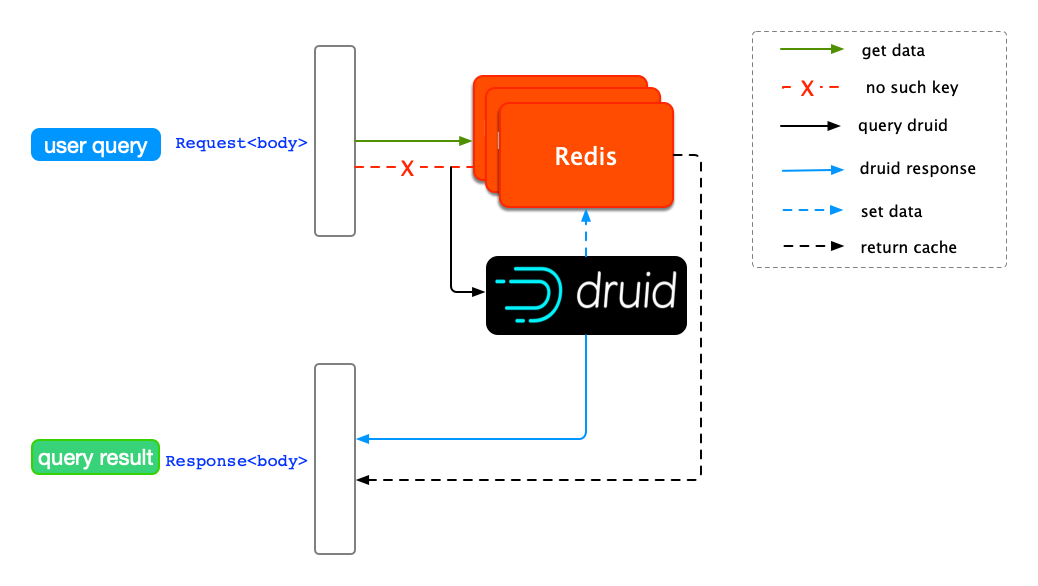
使用 Redis 缓存查询结果
最简单的缓存设计就是使用Druid的query body()作为key,Druid的 body()作为value。上述缓存机制的缺点很明显,只能处理查询条件完全一致的重复查询。在实际应用中,查询条件往往是多变的,尤其是查询时间的跨度。
例如,用户在相同的指标和维度组合下发起两次查询。第一个查询是从 10 月 1 日到 10 月 7 日的数据。 Druid 找到结果并将它们缓存在 Redis 中。用户将时间跨度调整为10月2日到10月8日,发起第二次查询。这个请求不会命中Redis,需要Druid查询数据。
从例子中我们发现两次查询的时间跨度的交集是从10月2日到10月7日,但是这部分的缓存结果没有被复用。在这种查询机制下,查询延迟主要来自于 Druid 处理重复请求,缓存的结果没有被充分利用。
提高缓存重用
为了提高缓存重用率,我们需要增加一个新的缓存机制:当查询在Redis中没有直接命中时,首先扫描Redis,看看查询中部分时间跨度的结果是否已经被缓存提取命中结果,未命中则查询德鲁伊。在扫描过程中,被扫描的对象是一个单位时间跨度的缓存。
为了获得任意单位时间跨度内的缓存,Redis中除了缓存单个查询的结果外,还需要将总跨度进一步按照时间粒度平均划分,缓存对应的结果所有单位时间跨度(如下图所示)。
Druid 结果按时间粒度缓存
Redis IO
从上图我们可以看出,需要对Redis进行一次读操作,来判断每个单位时间跨度的结果是否已经被缓存。当用户查询次数增加时,该操作会对 Redis 集群造成比较大的破坏。 Redis 连接的负担偶尔会超时。为了减少对 Redis 的 IO,我们为时间跨度设计了一套缓存机制。基于减少读操作的思想,我们设计通过一次读操作获取所有已经缓存的时间跨度,然后一次性读取所有缓存的结果。
为了一次获取缓存的所有时间跨度,我们需要缓存查询请求及其在每个缓存的 Druid 查询结果后所覆盖的时间跨度。在 Redis Key-Value 规则中,我们首先把查询体( )去掉时间跨度,生成一个与时间无关的查询体(est)作为缓存键;提取查询粒度(一次读取所有缓存结果,通过Redis的MGET获取est对应的每个时间戳。判断当前请求的所有单位时间跨度是否都命中缓存,直接返回命中结果。优化后的缓存机制如下图所示:
Redis 读操作优化
德鲁伊查询时间跨度长
在缓存未命中的情况下,设置较长的查询时间跨度(长时间跨度:2周以上),Druid往往会减慢返回速度,甚至阻塞其他查询请求。
我们测试了长跨度查询请求对整个集群的影响。通过分析 Druid 集群的监控数据,我们发现被长跨度查询命中的节点会出现内存消耗过大的问题。随着时间跨度的增加,内存消耗增加,甚至出现内存不足导致节点不响应的问题。
一个处理一个请求
调查了Druid的执行原理,我们发现一个查询请求只会路由到一个节点,通过节点找到目标数据在Deep中的存储位置,最后返回的数据也是通过节点来组合返回的结果。查询时间跨度越长,对 的压力越大,内存消耗也越大。
单处理长跨度查询
一个请求多次处理
单一性能无法满足长期查询。为了提高查询性能,我们尝试将 N 天数据的查询拆分为 N 个查询,每个查询仅 1 天,然后异步处理这些请求。发出来,结果N个请求很快就被返回了。与拆分前的查询时间相比,拆分后的时间大大减少。
长跨度查询的多次处理
从节点监控的角度来看,当一个长期的查询请求被多个处理时,可以减少单个的内存消耗,加快整体查询速度。加速等级请参考下图中的测试对比。测试用例使用了一天平台的所有查询。测试方法是将这些查询异步“回放”到 Druid,而不用打 Redis。
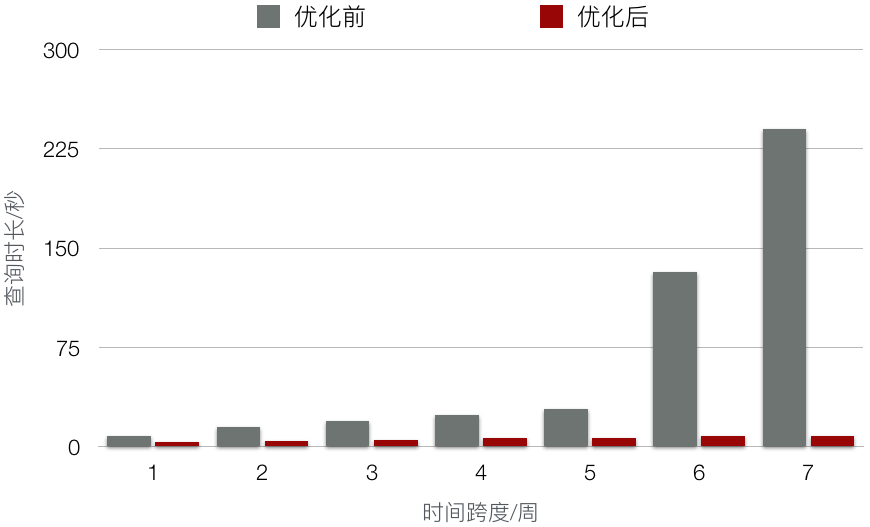
根据上面查询过程中的工作原理,为了加快长期查询的速度,我们需要在用户发起查询后拆分请求。拆分机制根据每个查询请求的查询时间粒度来确定。例如,对于上述 N 天跨度的天粒度请求,在查询到达 Druid 集群之前,我们尝试将其拆分为 N 个 1 天跨度。日级粒度请求。整个查询从分裂到命中Druid的过程如下图所示(Druid内部的详细工作请参考上文)。
按时间粒度拆分用户查询请求
缓存结果过期
前两步已经完成了从高负载下查询性能低、查询时间跨度长、速度慢、Redis复用率低到查询性能高、Redis IO稳定的演进。
分析平台的数据源来自离线数仓的Hive和实时数仓的Kafka。将上游数据重新摄取到 Druid 后,时间列对应的文件将被重新索引。文件索引重建后,对应的 Druid 查询结果也会发生变化。出现这种情况时,用户从 Redis 获取的结果没有及时更新,就会出现数据不一致的情况。因此,一套平台用户感觉不到的缓存自动失效机制就显得尤为重要。
自动缓存失效
在Druid查询链接下,可以抽象出一个数据源的最新成功摄取时间为其最新版本号。使用这个想法,我们可以用数据版本标记每个数据源。数据更新后,将新标签替换为更新后的数据源。这样,每次检查 Druid 查询结果是否过期时大数据培训是骗局,都有一个引用对象。
Druid 支持 MySQL 存储元数据信息( ),元数据中的时间戳只能作为数据版本。用户发起查询请求后,依次取出Redis缓存结果中携带的时间戳和MySQL元数据版本,然后将两者进行比较。如果Redis缓存的时间较新,说明缓存没有过期,直接返回缓存结果即可;否则,说明Redis缓存的数据已经过期,直接删除Key-Value对,然后查询Druid。
添加数据版本验证后,一个请求的整个生命周期如下图所示。
自动缓存失效机制
总结
本文重点介绍知乎数据分析平台对Druid的查询优化。通过一套自研的缓存机制和查询转换,目前平台长期满足业务指标和灵活分析的需求,降低了数据开发者的开发成本。
数据分析平台上线后,提供了非常灵活的能力。在实践中,我们发现过度的自由不一定是用户想要的。适当的流程约束有助于降低用户的学习成本,大大提升平台业务的查询体验。在早期,我们并没有对数据摄入施加太多限制。在数据稳定性提升的整个过程中,我们通过与数仓团队的强强合作,优化了摄入的数据源,包括限制高基数维度等治理工作。本文的缓存思想不仅可以用在 Druid 中,还可以用在其他 OLAP 引擎的查询优化中。
团队介绍
知乎大数据平台团队隶属于知乎技术中心。面对业务的多元化发展和精细化运营,对数据的需求越来越大,大数据平台团队主要负责:
随着知乎业务规模的快速增长和业务复杂度的不断增加,我们的团队面临着越来越多的技术挑战。欢迎对技术感兴趣,渴望技术挑战的朋友加入我们,共同打造知乎的数据平台。
