本文来自节目王粉的个人经历,分享两个大数据培训的求职心得,希望能给大家一些经验参考
过来拍个镇楼照片

王也因为投稿程序私下和他微信聊天,目前正在工作中
教育经历
坐标:北京
背景:普通书籍两本,非计算机专业,培训背景,工作时间四个月
职位:大数据开发
打包:项目由培训机构提供(推荐系统、用户画像、离线数仓、实时框架),加上自己对大数据的理解,优化修改
转行前背景:本人工作五年,曾在多个行业(物流仓储、仓储技术支持、项目管理、培训演示、审计)工作,具有较强的业务理解能力
获得报价
目前的工作:
外包公司,派人到银行负责用户画像开发工资(16k*13)
采访:
外包公司面试--
自我介绍
1.kafka 是如何消费的?
2.如何保证数据幂等性
3.spark和MR有什么区别
A面面试--
自我介绍
Spark、Flink 架构及底层运行原理
HQL 中的 on 和 where 有什么区别
spark的job stage任务和spark的执行顺序如何划分
采访总结:
基本上都是简单的问答,技术要求不是很高。实际开发,即编写HQL语句和shell脚本,ETL和存储。
工作总结:
银行的外包工作基本上是一些手工工作。一般来说,架构、设计和调优等技术是无法获得的。主要工作内容是编写脚本。工作内容轻松,基本没有加班。
报价:
某国企下属事业部,主要从事商业和军用遥感大数据产品,大数据团队很小(5人)
待遇:15*14+加无限期项目结账奖金(需从项目收益中获得大数据培训是骗局,无具体金额)
工作内容:大数据部分的开发也可能支持前后端开发。因为是卖产品的,所以还要负责跟甲方沟通,后期可能负责主导大数据外包的发展。
描绘的前景很好,但考虑到国企制度的刚性,在技术敏感性上可能没有那么好。另外,由于遥感大数据并非市场主流,后续的跳槽也可能会产生一定的影响。
采访内容--
一面(视频采访)
自我介绍
1.存储了关于组件的哪些信息
2.没有它就无法使用Kafka
3.spark 运行过程
4.火花宽度依赖性
5.flume和Kafka的区别
6.你对机器学习了解多少
第二面(现场面试)
自我介绍
自我介绍后没有问任何问题。 . 直接让HR过来跟我谈薪水
自我介绍的内容主要包括
Flume、Kakfa、canal、mysql、Hbase、hive、spark,一系列完整的闭环架构
主要说明数据可靠性、后续扩容升级方向、优化、二次开发等,以及业务需求。
(其实面试了4家公司,有3家公司开出20K-30K的工资,但是他们明明要求过去带队……所以就剩这个了。)
大数据进入行业发展
因为我是培训机构的,所以我主要讲培训。
主要有两种身份--
1.新生
应届毕业生进入行业有两种情况,一种是打包简历,一种是不打包简历。
让我们从不打包简历开始。市场上有很多公司专门选拔985、211名应届本科生进行培训。当然,工资也会相应降低。
我们来谈谈包装简历。一般打包简历后,如果技术不够强,很多人只能选择外包公司转型,而且由于毕业时间的限制,打包的内容也很有限。
据我所知,其实如果你想转行,最好从你的大四三、大四开始学习这方面的知识。越晚越吃亏。
2.有工作经验的人
我属于这种情况。如果想起来不是很困难,我不建议选择这条路。一是沉没成本太高,二是每个人对技术的接受程度差别很大。
目前,由于培训机构在大数据发展方面的不断努力,市场越来越满。初级职位基本没有,中级职位竞争激烈。
如果你下定决心要走这条路,有几个小建议。一种是请业内人士帮你分析,包括你有没有自己的优势,学习一些技术基础,业内人士和业内人士。外人看待问题的视角和视角存在巨大差距。
正在寻找大数据开发方面的工作:
目前市场上有几种类型的工作
1.外包
主要有两种类型,项目外包和人员外包。外包公司虽然名声不好,但进入门槛低。想进入这个行业,可以先做一个跳板,再努力谋发展。
2.非外包
基本上,要么是大数据平台,要么是内部服务。或者是卖大数据产品。
求职注意事项
在大数据领域,有很多皮包公司是卖狗肉的,叫你过来面试,然后骗你去培训,才能找到工作。这种东西可以直接留下,不要浪费你的精力。
工作职责非常重要。建议您在面试前仔细阅读。从岗位职责上,基本可以看出公司缺谁。这样可以提前做好准备,效果也不错。
几年前大数据培训是骗局,大数据开发对开发语言的要求不是很高,但是从年初开始,对java和Scala都有一定的要求,但是培训机构还没有回应问题,并没有意识到问题的严重性。性,注意自己。
大数据技术栈不多,面试题角度基本不变。你可以在网上找到更多的面试题,求同存异。
学习笔记
因为我也是菜鸟,不敢说出来,所以跟大家分享一下我的学习路线
首先,培训机构教的东西很基础,很重要。但是培训机构的项目基本都是伪代码,需要自己去优化。网上搜了很多大数据优化,尽量让项目成功,没有逻辑Bug。
除了本机构的知识,如果平台是B站,还可以在网上看一些其他机构的培训视频。
还有一些书籍可以看,开源组件的权威书籍。如果实在没有时间,建议至少阅读优化部分。一是在面试的时候,可以很轻松的看懂面试题,二是在实际工作的时候,对你有一定的帮助。
也因为大数据架构是相通的,所以遇到看不懂的知识点也没关系,可以继续学习,到最后就会明白。
当你更多地了解大数据技术后,你会发现为了满足一定的要求,不同组件的底层运行原理很可能是相同或非常相似的。
源码部分,如果基础好,一定要多看;如果速度快的话,也应该挑一些重要的去读,自己写一些,比如Flume的二次开发源码修改,比如spark的RDD源码,就看你自己的能力了。
最后,如果你选择了这条路,一定要坚持下去,让学习成为一种习惯,否则你很快就会被市场淘汰。
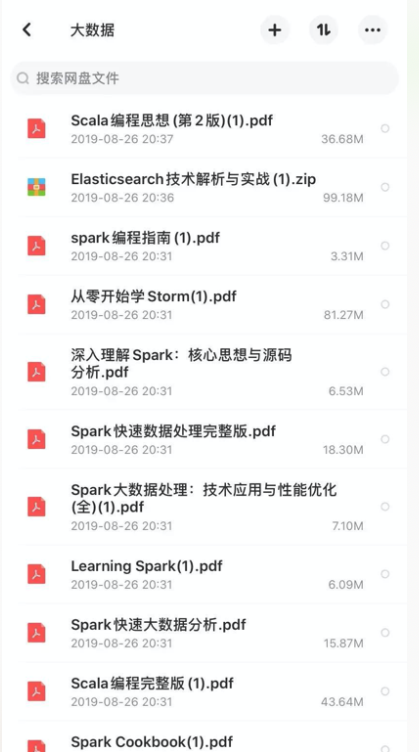
11款优质大数据定向资料
获取方式,扫描下方二维码回复:大数据
